






Learning to recommend what agents should do
At ASAPP, we build AI models to increase the efficiency and effectiveness of customer service agents by recommending the next action to perform during live chat. A natural starting point for creating such models is to learn to predict when the agent would perform the action based on the data we have collected in production. The data we collect are usually of the form: timestamp & event. For example:
14:28:03, AGENT ASSIGNED TO AN ISSUE
14:28:44, AGENT SENDS A MESSAGE
14:29:18, AGENT CLICKS AN AUTOMATED RESPONSE
14:31:52, AGENT ENABLES AUTOMATIC TIMEOUT TO TAKE OVER
For example, our AutoSuggest model learns the likelihood that an agent will send a certain message based on the context of the conversation and other features. Our AutoCompose service uses this model to surface the most likely next message as a suggestion to the agent, reducing their response time, lower cognitive load, and encouraging them to use preferred phrases. The actual next message sent by the agent has proven to be an effective target for AutoCompose, resulting in high usage, reduced average handle time, and positive feedback from agents.
However, sometimes what agents actually do, isn’t necessarily what they should do. And what agents actually do in production is the raw data that’s logged. If we are not careful, this is the data that will be used to train AI models, which will reinforce suboptimal agent behaviors through recommendations and automation.
This was the situation with our Automatic Timeout feature and our Flexible Concurrency feature. Automatic Timeout is an automation feature that agents can opt in to when the customer has likely left the chat. The feature will send timeout messages on behalf of the agent so that the agent can focus their effort elsewhere. The feature was a huge success in increasing agent efficiency and extremely popular with agents.

We discovered that agents would manually time out customers rather than use the feature to avoid receiving additional assignments.
Chris Fox
To improve usage of Automatic Timeout, ASAPP developed a recommendation model to recommend the Automatic Timeout feature to agents. The most natural starting point seemed to be predicting when agents were likely to use the feature, based on the usage data we had collected in production. But, there was a wrinkle.
Soon after Automatic Timeout went live, our AI-driven Flexible Concurrency feature was launched. This feature learns and predicts agent busyness. When it predicts the agent is likely to not be busy, the agent’s concurrency can be increased (flexed) without overwhelming the agent. One of the biggest predictors of an agent’s busyness is whether Automatic Timeout has been enabled. Agents began to notice that there was a correlation between using Automatic Timeout and increased concurrency. Because companies typically tie agent performance to agent handle time (rather than their throughput), agents are not incentivized to take on additional issues. As a result, usage of the Automatic Timeout feature decreased. Agents would manually time out customers rather than use the feature to avoid receiving additional assignments.
Because some agents were not using Automatic Timeout to avoid additional issue assignments, many timestamps where a recommendation would be relevant were incorrectly labeled as times not to recommend.
As an alternative to leveraging agents’ past usage of Automatic Timeout as the prediction target, we explored instead labeling each timestamp based on whether there would be no further customer actions after that point in the chat. This approach had the advantage of not being affected by some agents’ preference to manually time out the customer. It captured all cases where the customer became idle during the chat. Moreover, the model achieved high accuracy on this prediction task.
However, upon further testing, we discovered that this prediction target was in fact not as good a choice as it first appeared. The model was recommending Automatic Timeout very frequently during the end of normal chats, in which the customer issue had been resolved and the agent was closing out the conversation. The predictions were highly confident in these sections of the conversation.
Meanwhile, in cases where the customer had gone idle while the agent was waiting for them to respond, the model often predicted no recommendation or had low confidence. Looking further into the data, the reason was clear: normal chats are far more common than chats in which the customer leaves the agent waiting. As a result, the model focused on detecting normal chat endings, and worse, our evaluation metric was largely reflecting model performance in those irrelevant situations.
This is an example of a common issue in the application of AI models: the usefulness of a model depends on choosing the prediction target carefully. A poorly selected target can result both in a model that is ineffective for its intended application and an evaluation metric that obscures this fact from the model developer.
We considered further restricting the target to require, not only that the customer was inactive, but also that the conversation concludes by being timed out. However, it can be helpful for the agent to use Automatic Timeout to free them up temporarily to focus on other work, even when the customer comes back before the sequence completes in a few minutes.
In the end, we designed a more complex target that better identifies the times in the chat when it would be useful to enable Automatic Timeout, based on additional situational data and an auxiliary model. Specifically, the customer needs to have been idle for a certain period, and the next event in the chat is either an Automatic Timeout message, a timeout-like message sent manually by the agent, or the agent timing out the customer (which closes the chat and prioritizes the customer in the queue if they chat back in again). An auxiliary model is used to identify timeout-like messages. This work was primarily driven by our amazing intern Sara Price.
Data used to label Automatic Timeout recommendation model training data
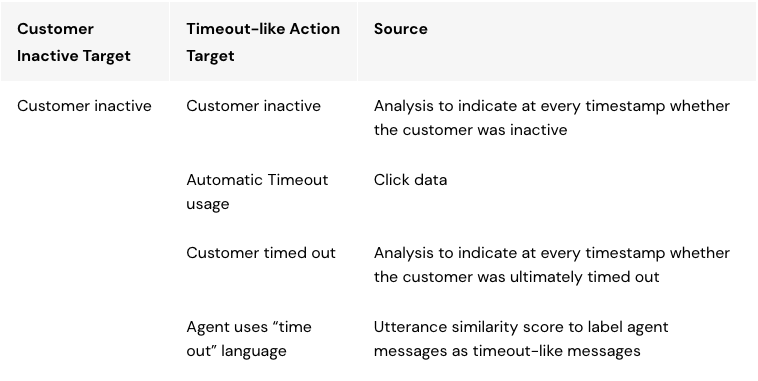
As you can see from the table above, labeling training data for the Automatic Timeout recommendation model based on what agents should do entails a lot more modeling effort than simply replying on what agents have been doing (using the feature or not). Fortunately, with the ASAPP AI Native® approach, the additional models needed to determine the type of language the agent is using are already available and can be easily consumed by the Automatic Timeout recommendation model.
With the final version of the prediction target, we achieved a better alignment between the training data, and hence the model’s behavior, and the usefulness of our recommendations. And the evaluation metric became a better indicator of how useful our model would be in practice. In some cases, simply predicting agent actions is sufficient to build helpful AI recommendations, but in other cases, as with Automation Timeout, we have found it can pay dividends to think carefully about how to engineer the training data to guide agents toward more optimal workflows.