Article
Video


From understanding customer issues to analyzing agent performance, voice analytics are crucial to operating an efficient, modern contact center.
From understanding customer issues to analyzing agent performance, voice analytics are crucial to operating an efficient, modern contact center.
But what exactly are call center voice analytics, and how can they be utilized to improve your contact center operations?
This blog post defines voice analytics and describes its potential benefits. Then, it walks through various use cases for voice analytics. Finally, it prescribes a framework for thinking through acquiring technology to improve your analytics.
Let's get started.
Analytics is the process of "discovering, interpreting, and communicating significant patterns in data." In other words, analytics is the art of transforming raw data into usable metrics.
Call Center Voice Analytics, also known as Speech Analytics, is the process of transforming conversational data from voice interactions into meaningful metrics.
Typically, speech analytics software will utilize advanced computing techniques, like machine learning and natural language processing (NLP), to input all conversational data between agents and customers and output digestible metrics.
Voice analytics might include some of the following metrics:
Real-time speech analytics enable contact center management to intimately understand how well their agents are servicing customers and accomplishing company objectives. In the next section, we break down the power of voice analytics for contact center management.
Voice analytics are to a contact center as the instrument panel is to a pilot.
With high-quality voice analytics, contact center management can keep their finger on the pulse of their organization. Below, we break down some of the use cases for live contact center analytics.
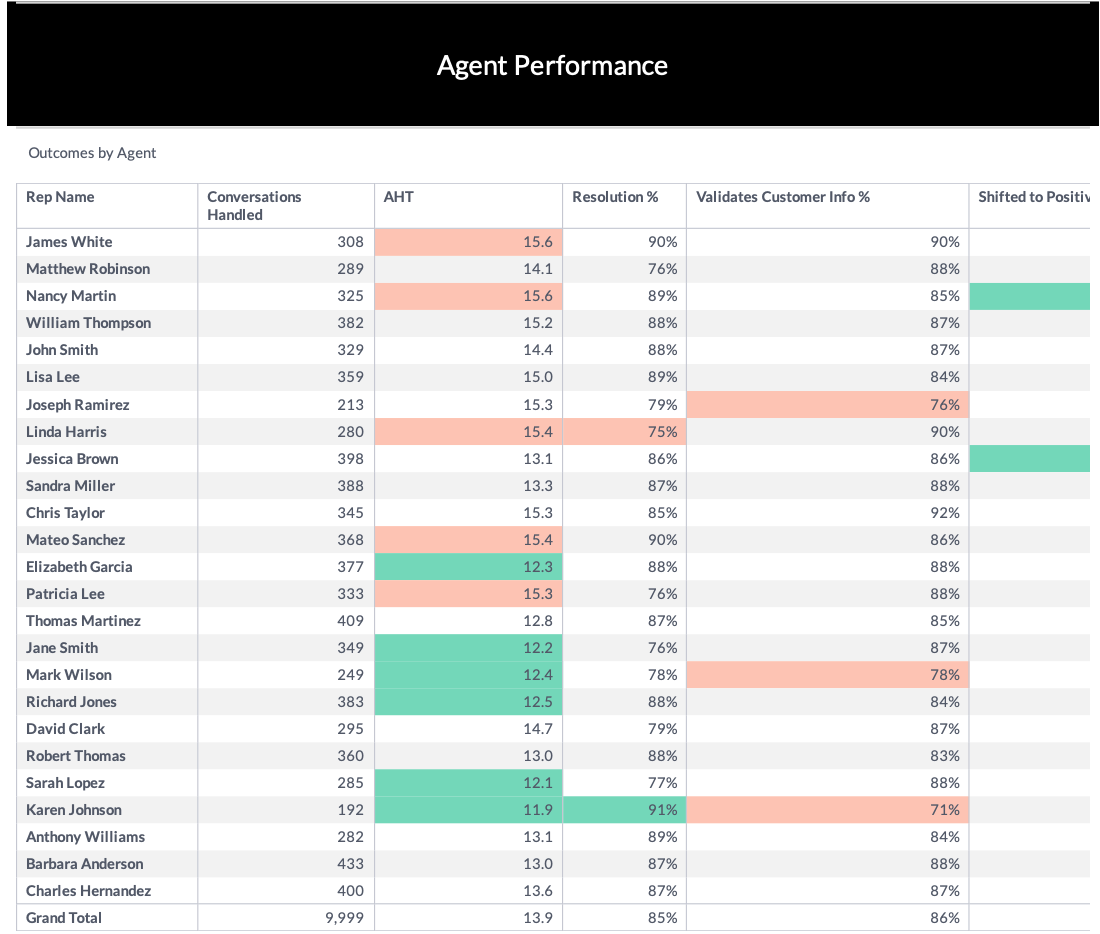
Voice analytics enable contact center management to understand the quality of the support its agents are providing. Analytics can help create a scorecard for agents, allowing management to see at a glance how agents are performing on a variety of metrics.
For example, a telcom company might need to weigh several variables when determining agents' performance. These variables might include average handle time, resolution rate, call back rate, and truck roll rate (the percentage of time a service truck is dispatched to a customer.) Voice analytics can compile all this data without manual intervention.
In addition, voice analytics can perform automated quality assurance work, like checking to determine if certain promos were offered, if policies around customer ID verification were followed, etc.
In short, voice analytics automates and simplifies quality assurance and performance management, while offering the ability for managers to gain visibility into a wide variety of metrics.
Similar to the above, analytics on customer conversations can provide documentation for compliance and help companies manage risk.
For example, if a company is required by law to provide certain information for specific products (like a disclaimer for a financial product), voice analytics can provide evidence of agents' compliance.
In addition, analytics can serve as a powerful risk management tool. By creating flags that monitor automatically for likely fraud, potential discrimination, and more, a speech analytics tool can help companies proactively manage risk.
Voice analytics can provide detailed information about customer issues, sentiment, satisfaction, and more by leveraging AI to analyze customer conversations.
By understanding exactly why customers are calling, companies can be proactive about resolving problems before they occur. In addition, contact centers might consider bolstering their bot flows to address common issues or creating automated internal processes to handle frequent requests more adeptly.
By utilizing the power of voice analytics, contact centers can identify trends as they occur and design intelligent interventions to improve customer experience.
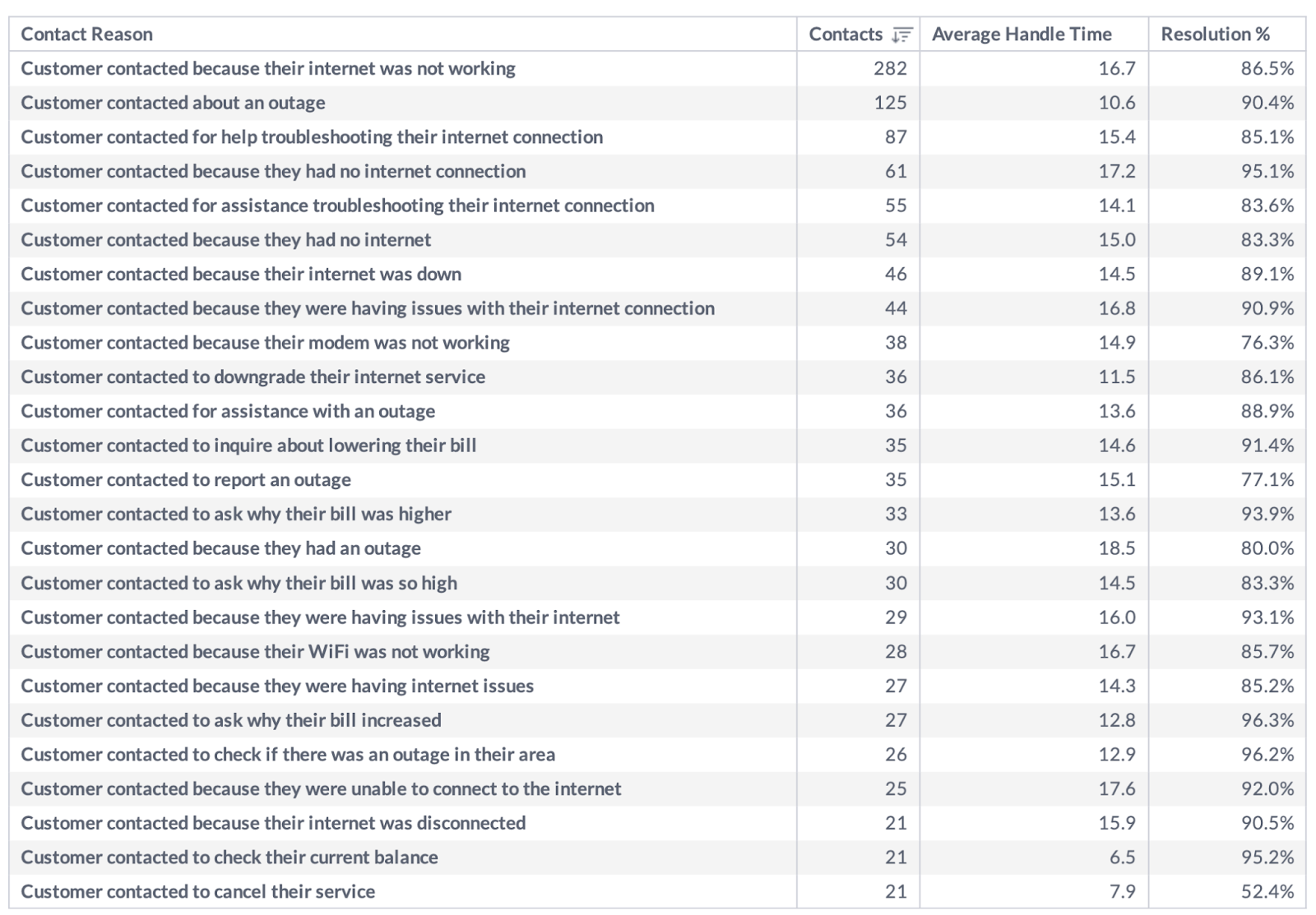
Voice analytics can do more than report simple metrics; it can also be configured to run complex operations, such as analyzing customer sentiment and intent and categorizing issues.
One of the most powerful ways to configure voice analytics is to leverage the various analyses it provides to automatically identify potential churn.
For example, suppose analysis demonstrates that customers most likely to churn are those who call at least three times in a week, demonstrate negative sentiment, and use profanity in at least one call. Voice analytics software can flag every case with these qualities so management can determine the best way to intervene and reduce potential churn.
Of course, in a real-world application, the analysis can be much more complex. But the power of voice analytics is that it helps to predict problems before they occur, so management can be proactive rather than reactive.
The best voice analytics software leverages the power of AI to automatically summarize customer interactions. With powerful automated summaries, contact center agents can significantly reduce the amount of after-call work needed to document interactions.

More, automated summaries can provide both structured and free text data. Structured data is standardized data, typically tabular with rows and columns, that clearly define data attributes. Best-in-class voice analytics software will automatically summarize call into defined, structured data that's relevant to operations (like competitors mentioned, whether a certain promo was offered, which products were discussed, etc.)
In addition, best-in-class voice analytics software can also provide informative free text summaries of conversations, enabling managers to quickly understand conversations without needing to dive through a transcript or rely on hurried agent notes.
With automated summaries, agents can significantly reduce the time spent on after-call work, and contact centers can receive enhanced summaries with the information they need to be effective.
Voice analytics software is incredibly powerful. It provides management with a bird' s-eye view of the contact center's operations, quality assurance and performance management, helping to ensure compliance, aiding in identifying and reducing churn, and analyzing customer trends. Meanwhile, it can also improve agents' experiences by helping to automate summaries, enabling them to focus fully on the customer.
But how should contact centers think about purchasing the right voice analytics software for their company? Below, we highlight some key qualities speech analytics software should possess to provide as much insight as possible:
Low-accuracy transcription will hold back your voice analytics. Transcription is the core of any voice analytics solution. It is the technology that converts speech to text, so the software can accurately analyze the conversation.
But what is low accuracy?
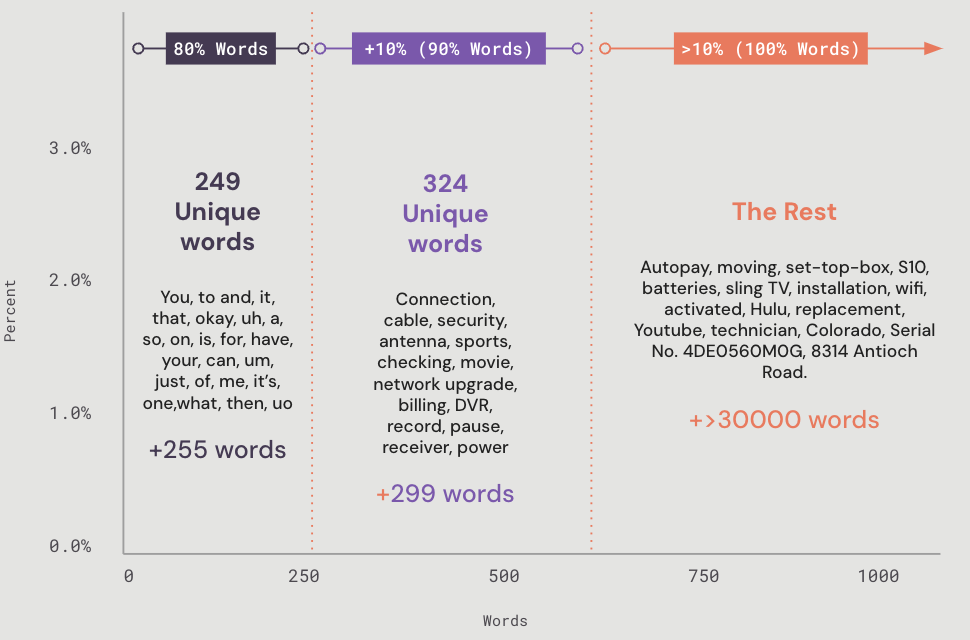
The roughly 80% accuracy that many transcription solutions tout may sound like it is good enough. However, when 80% of the conversation is composed of simple words, it is the last 20% that holds the most critical, company-specific information you need to fill in the blanks.

If the solution you are considering is only capturing common words and phrases, you are going to miss out on the most valuable information, such as specific products, services, or policies mentioned, technical details, order or serial numbers, and more. With transcription, the real story is in the details. Make sure your solution captures the most important ones.
The right transcription solution will even let you identify and extract the most critical entities that you would like to glean from the transcript, such as order number, product name, date of transaction, dollar amount refunded/charged/credited, last four digits of account number, and competitor name.
Most software offers cookie-cutter templates and insights that force companies to adhere to their definitions of what useful information to glean from customer conversations.
But every business is different, with unique use cases, nomenclature, and key issues to track.
The best software should enable your contact center to customize the valuable insights they want to glean from customer interactions.
Custom configurability should also extend to dashboards. Don't settle for pre-configured dashboards that limit your ability to understand what really matters. You should be able to customize dashboards to reflect the particular priorities and needs of management.
Your summary data should guide corporate policymakers, provide insightful analytics, and be used to arm your agents. For it to truly do this, that data needs to be structured in the following categories for optimal use:

Finally, any voice analytics software you choose should be able to integrate with the systems you use every day to access and manage customer data.
At a basic level, the software of your choice should be integrated with your CRM of choice, so it can automatically push automated summary data to the CRM without the need for additional agent actions.
In addition, the software should be compatible with your voice data, including audio via SIP call recording (SIPREC) protocol from contact center session border controllers (SBCs) or from live media stream services offered by major cloud telephony providers such as Amazon Connect (Kinesis), Twilio (Media Streams), and Genesys Cloud CX (Audiohook).
The right software should also be available both on-prem or as software-as-a-service.
In short, the best software is one that can mold itself to your infrastructure instead of forcing you to adapt to it.
Your conversation data is more valuable with ASAPP than any other solution. With our industry-leading structured data and enrichment capabilities, you will have more actionable insights and data discoverability than you thought possible - without any additional work for your agents. All this while dramatically reducing AHT, slashing ACW, and building a solid data foundation for all AI solutions to come.
ASAPP AutoSummary automates 100% of agents' after-call work. By combining human-readable and insights-ready summaries, AutoSummary can offload monotonous tasks for your agents and enable consistent, unbiased data across your contact center.
Beyond automatic and accurate summaries at scale, AutoSummary differentiates itself from other solutions by providing industry-leading capabilities around enrichment, structured data, configurable insights and dashboards, and flexible integrations.
In addition, ASAPP AutoTranscribe is the fastest and most accurate generative AI transcription solution purpose-built for CX. Only ASAPP delivers industry-leading speed and accuracy without compromising either.
If you are sold on the need for the most powerful and configurable voice analytics software, then you need to know what to look for (and what to look out for) when evaluating solutions. Just “good enough” isn’t good enough when you are setting the foundation of intelligence for your CX organization.

This guide will help you understand the features and capabilities you need to keep in mind when evaluating solutions and the reasons why they are mission-critical for your organization. Read on to ensure you aren’t adding to your technical debt and that you are building a solid foundation for your AI journey with the right solutions.
Before diving into the solutions, let's take a moment to understand why ACW (After Call Work) matters in call center operations. ACW plays a crucial role in ensuring accurate record-keeping, compliance with regulations, and follow-up actions after customer interactions. It's the behind-the-scenes work that agents undertake to maintain high-quality customer service standards.
While these tasks are essential, they pose significant challenges for agents and contact center operations due to their ongoing conflict with the goal of reducing Average Handle Time (AHT). This natural tension between lowering AHT—a critical performance metric—and thoroughly completing all necessary tasks during ACW requires a delicate balance. Managing these competing priorities creates ongoing difficulties in optimizing contact center efficiency and effectiveness.
To address this, let’s explore the unique challenges of ACW, highlight the main contributors to ACW, and showcase how advanced generative AI is alleviating the tension between ACW and AHT.
When we talk about ACW, we're referring to the tasks that agents must complete post-call. These tasks include updating customer records, logging call details, completing forms, and ensuring compliance with company policies and regulations.
Now, let's break down the main factors contributing to ACW:
One common, well-known challenge in ACW is the time-consuming nature of manual tasks, leading to delays in follow-up actions and reduced agent productivity. However, the challenges extend beyond time constraints and encompass various aspects of data management and analysis. Here are some additional challenges:
Optimizing ACW processes can lead to significant benefits for call centers, including improved agent efficiency, enhanced customer satisfaction, and better compliance with regulatory requirements. By streamlining ACW tasks, call centers can deliver a more seamless and personalized customer experience.
Alleviating the Tension Between ACW and AHT
Advanced generative AI now has the power and nuance to effectively manage the tension between reducing Average Handle Time and completing essential After-Call Work tasks. These elevated automation capabilities raise the ceiling on what's possible with the majority of customer interactions. Generative AI can efficiently handle more complex customer issues with minimal human oversight, enabling agents to concentrate on addressing more intricate issues and engaging in higher-level tasks.
Generative AI's capacity to streamline processes not only reduces AHT but also ensures the thorough completion of crucial ACW tasks. This balanced solution optimizes contact center efficiency and effectiveness with proper escalation management, empowering agents to operate more efficiently with the support of generative AI.
ASAPP's summarization solution, AutoSummary, is making a big impact in streamlining post-call tasks and creating rich information for analytics and operational enhancements. AutoSummary automates the summarization of customer interactions, reduces ACW processes, provides real-time operational feedback, and empowers agents to work more efficiently while solving customer problems faster.
Call Center ACW (After Call Work) is a critical aspect of call center operations, and understanding it is essential for success. With the right tools and knowledge, call centers can streamline ACW processes, improve agent efficiency, and deliver exceptional customer experiences.
Ready to dive deeper into the world of ACW and learn how to optimize your call center operations? Check out our eBook, “The Modern CX Guide to Summaries.” In it, we explore advanced strategies for reducing ACW and improving overall efficiency and unpack how modern solutions to summaries and dispositioning can slash ACW.

Average Handle Time (AHT) is a key contact center metric. In short, AHT measures the average time of a customer interaction.
AHT provides crucial information about contact center efficiency, staffing needs, and customer experience. And as such, AHT is one of the essential metrics for contact centers to track.
In this blog post, we define AHT and show you how to calculate it. Then, we discuss six impacts reducing AHT can have on your organization. Finally, we provide recommendations for how to reduce AHT while optimizing customer experience.
Average Handle Time (AHT) is a core call center KPI that measures the average time for an agent to handle a customer interaction from start to finish.
AHT encompasses the entirety of an agent's interaction with a customer issue, including total talk time, hold time, and after-call work (ACW).
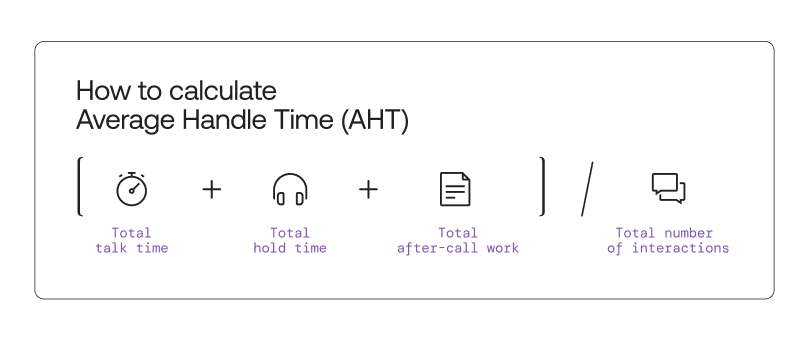
The standard formula to calculate AHT is adding total talk time, hold time, and after-call work and dividing by the total number of interactions.
Talk Time: The time an agent spends actively engaging with a customer
Hold Time: The time an agent spends while a customer is on hold
After-Call Work: The time spent on work that needs to be completed after a call or interaction before the next interaction can start.
In formula form, AHT is calculated as:
Average Handle Time is one of the most important KPIs for any contact center to track because it impacts both contact center efficiency and customer experience.
Average Handle Time distills the time spent across interactions and averages it by the amount of interactions. This one metric impacts the entire contact center organization. Understand AHT and understand how to do the following:
Understand how many agents are necessary to handle expected case loads. The lower your AHT, the higher the total number of calls your agents can handle in a given time period.
Compare your AHT to standards across your industry to understand your relative performance.
Measure your AHT over time to understand if your contact center is more efficiently handling issues, satisfying customers, and effectively utilizing resources.
AHT can be helpful for analyzing both overall contact center performance and individual performance. While other call center metrics, like customer satisfaction and containment rate are essential to contextualizing the entire picture, AHT can be helpful to understand an agent's capacity and efficiency.
If your AHT is higher than expected, it can be helpful to analyze the individual components of the metric (talk time, hold time, after-call work) to determine where your contact center might need the most improvement.
With this information in hand, you can invest in additional training or update your technology stack with modern software that improves agent efficiency and reduces hold time and after-call work.
Customers want their issues to be resolved quickly and efficiently. AHT is one of several metrics that helps inform management about how quickly customer issues are being handled. A low AHT implies the following for customers:
Nobody likes waiting on hold. Reducing AHT by reducing the time customers spend on hold or in a transfer improves customer experience.
AHT is a proxy for the time it takes to resolve a given issue. Reducing AHT means customer's issues are being resolved more quickly.
Shorter wait times and faster issue resolution contribute to greater customer satisfaction. Work to improve AHT to ensure your customers are having their issues meaningfully resolved quickly.
What you pay attention to grows.
If you want to reduce AHT, the first step is to monitor AHT.
Then, set realistic goals, supported by process and technology changes, to reduce AHT over time.
Modern CX software, like ASAPP, can help you automatically track metrics like AHT over time.
The most efficient way to reduce AHT is to help customers resolve an issue without needing an agent’s support.
But true self-service is more than simply putting a manual’s worth of information online and making it searchable through a help function.
Modern self-service design should leverage modern virtual agents that go beyond simplistic chatbots to handle a broader array of issues, provide more realistic responses, and solve more customer issues before an agent ever needs to get involved.
To reduce AHT, contact centers should provide agents with the tools they need to facilitate resolutions quickly and meaningfully.
Digital features that can augment agents include:
One of the largest contributors to talk time and after-call work is time spent taking notes and writing call summaries.
The time required to take these notes can often be around 10% of the actual call duration and is one of the greatest contributors to high AHT.
With such a large percentage of time consumed by agents taking notes, contact centers are put between a rock and a hard place. If they press agents to reduce their ACW by taking notes during a phone call, it can often lead to prolonged pauses that reduce customer satisfaction. On the other hand, if they ask agents to reduce overall time spent taking notes, it can lead to gaps in summaries that might impact other agents down the road and make it difficult for supervisors to have good visibility.

In short, traditionally, AHT has been difficult to reduce without reducing customer satisfaction. In particular, attempts to reduce ACW by shifting notes into phone calls can either increase talk time or reduce customer satisfaction to an extent that can undermine the initiative altogether.
But now, with modern CX technology, like ASAPP, contact centers can both reduce AHT and increase customer satisfaction.
ASAPP AutoSummary leverages AI to automatically take notes and summarize calls, so agents can focus on the clients. Importantly, ASAPP AutoSummary creates accurate, data-rich, and easily accessible summaries that contact centers and their agents can trust.
With AutoSummary, companies can significantly reduce their AHT and ACW while enhancing the customer experience. In fact, in one case study, ASAPP AutoSummary reduced after-call work from 10% of call duration to just 3% of call duration.

Struggling with agent notes, lengthy after-call work, questionable questionnaires, cumbersome compliance checklists, lack of context for calls, and a lack of definitive understanding of WHY your customers are calling you?
The answer to all of these struggles is the ability to have good summaries at scale.
Unfortunately, you are likely not getting all your business needs from them. Worse yet, they distract your agents from customer conversations and add crucial time to your AHT. This eBook is here to help.
This eBook will cover the best practices and technologies that will deliver the value that good summaries promise without undue agent distraction. Readers will learn:
The future is here.
ASAPP GenerativeAgent®, AI-powered chat and voice agents, can empathize with customers, understand complex problems, and access internal APIs and processes to provide helpful answers or initiate actions to solve user problems (with company approval, of course.)
Use GenerativeAgent to resolve issues before an agent needs to become involved. GenerativeAgent can substantially reduce AHT by drastically reducing the time agents spend on interactions and minimizing after-call work. By enabling greater concurrency, Generative Agents increase the number of calls handled in a given period.
Interested in how GenerativeAgent could transform CX? Read more about GenerativeAgent here.
ASAPP is the AI-native software for contact centers, and ASAPP exists to end bad customer service.
We help customer service leaders unlock their full value by minimizing costs & inefficiencies, improving agent compliance & productivity, and surfacing actionable insights while helping you deliver a great customer experience.
Our customers are large enterprises who care deeply about leveraging AI to transform CX by delivering unprecedented cost savings and improving customer satisfaction.
We make a full suite of AI-native solutions designed specifically to help companies reduce AHT and improve customer experience.
Mastering Average Handle Time (AHT) is essential to operate efficient contact centers and enhance customer experience. By understanding AHT and implementing key strategies to reduce it, contact centers can drive efficiency and delight customers.
Transcription and Summarization solutions are not only the foundation of CX intelligence; they are a foundational capability for your AI strategy as well, so you better choose the right ones.
This guide is here to help.
Not all transcription and summarization solutions are built the same. While some may seem “good enough,” those same products can introduce crippling technological debt, may hamper the effectiveness of your other technology solutions, and may fail to surface the discoverable and actionable insights that you were hoping to achieve.
If you are serious about finding the right transcription and/or summarization solution to reduce AHT, this guide will help you understand:
GenerativeAgent can substantially reduce AHT by drastically reducing time agents spend on interactions and minimizing after-call work.
To deliver exceptional customer experiences at scale, it's critical to recognize the indispensability of accurate, fast, automated transcription. Serving as the cornerstone for comprehending customer needs and preferences at scale, high-quality transcription captures the nuances of every interaction, ensuring no critical insights are lost in translation.
This foundational capability empowers contact centers to make well-informed decisions, boost operational efficiency, and provide unmatched customer satisfaction.
As enterprises grow and customer expectations evolve, the need for top-notch transcription solutions becomes even more pronounced. Quality transcription improves data integrity and enables organizations to extract actionable insights from vast amounts of customer interaction data. With the right transcription solution, contact centers can transform data swamps into navigable data lakes, laying the groundwork for future AI endeavors.
In recognizing the critical importance of quality transcription for driving superior customer experiences, ASAPP developed AutoTranscribe with a keen focus on accuracy, speed, and scalability. By understanding that precise transcription forms the bedrock of effective customer interactions, ASAPP AutoTranscribe stands out as a solution meticulously crafted to meet the unique demands of modern CX environments. With its commitment to high accuracy, unparalleled performance, tailored CX models, and rigorous evaluation processes, AutoTranscribe ensures that organizations can harness the power of transcription to elevate their contact center operations and deliver exceptional customer satisfaction.
When you are thinking about the performance of transcription solutions, the two metrics that matter the most are accuracy and speed. Here’s why.
Most transcription services handle basic conversations well, capturing over 80% of conversations that involve simple words and phrases. However, the real challenge lies in the remaining 20%—the complex, company-specific information critical to understanding and action. AutoTranscribe shines here, offering unparalleled accuracy in transcribing the nuanced and evolving language found in live, human-to-human interactions.
In dynamic live interactions, whether it's a call or chat, every second counts. ASAPP AutoTranscribe stands out as the fastest transcription service, enabling agents to quickly access transcribed content and provide real-time support to customers. This translates into instantaneous responses and seamless information processing, ensuring that interactions progress seamlessly and efficiently.
The most accurate transcription
So you won’t miss the key details showing you exactly what happened in every call
89%+ Accuracy
The fastest transcription
Because real-time problem-solving requires real-time transcription
60ms Latency
Focusing on contact centers, AutoTranscribe is built on a foundation of real-world data, utilizing actual calls between agents and customers in its training data. This specialized approach allows for best-in-class performance, significantly outpacing generic transcription services.
Each deployment is fine-tuned to the client's specific domain, achieving a word error rate (WER) of less than 11% with continuous improvements. The technology boasts low-latency performance, generating text in less than 60ms from the end of an utterance, ensuring conversations are captured seamlessly and accurately.
Low-accuracy, high-latency transcription is holding back your contact center.
80% accuracy may sound like it is good enough. However, when 80% of the conversation is composed of simple words, it is the last 20% that holds the most critical, company-specific information you need to fill in the blanks.
The practical benefits of adopting AutoTranscribe are numerous and impactful. For contact centers, the solution's real-time audio processing capability integrates smoothly with standard telephony systems and supports live audio streams, simplifying implementation. By creating and maintaining models that are uniquely tailored to each business's specific needs, AutoTranscribe ensures that critical vocabulary and phrases are accurately captured, enhancing the customer service experience.
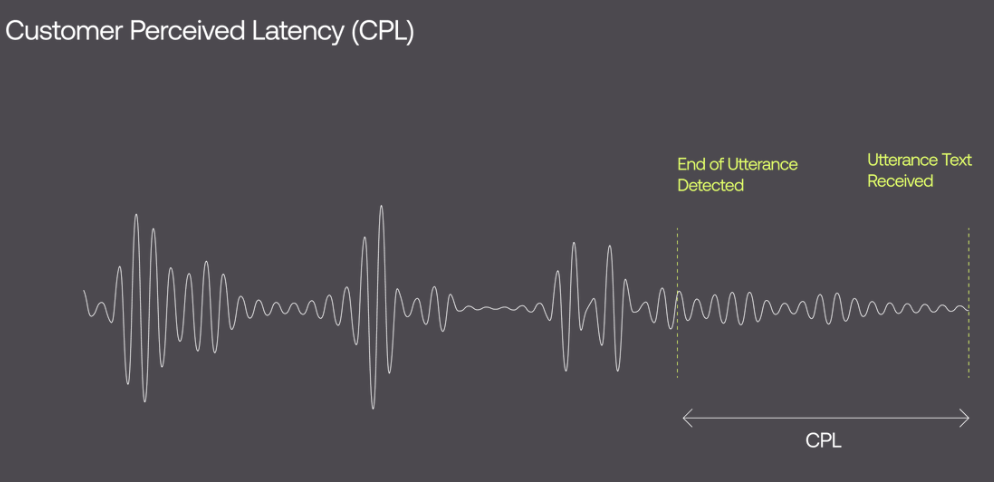
Real-time problem-solving requires real-time transcription.
In a live call or chat scenario, speed is of the essence. ASAPP AutoTranscribe impressively achieves remarkably low latency, enabling human and virtual agents to access transcribed content, swiftly enhancing their efficiency, enabling real-time responses and information processing.
ASAPP's commitment to ongoing research and development means that AutoTranscribe clients benefit from the latest advances in speech recognition technology, continually improving accuracy and performance. This dedication to excellence and customization makes AutoTranscribe not just a tool but a strategic asset for enhancing the quality and effectiveness of contact center operations.
To realize the value of CX AI technology, highly accurate, real-time transcription should be your first step. Otherwise, your agents, AI solutions, and bots won’t have the information they need when they need it, and the benefits you may be expecting from generative AI solutions will be stunted.
If you have plans to evolve the effectiveness and efficiency of your CX organization, then only AutoTranscribe will do.
For comprehensive insights into CX transcriptions and their transformative potential, download our eBook "The Modern CX Guide to Transcription." Explore best practices, technologies, and solutions to revolutionize CX with accurate transcription. Elevate agent efficiency, gain valuable business data, and harness the full potential of customer interactions.
Transform your CX strategy with the right transcription solution.

ASAPP is the AI-native software for contact centers, and ASAPP exists to end bad customer service. We help customer service leaders unlock their full value by minimizing costs & inefficiencies, improving agent compliance & productivity, and surfacing actionable insights while helping you deliver a great customer experience. Our customers are large enterprises who care deeply about leveraging AI to transform CX by delivering unprecedented cost savings and maximizing customer delight.
Want to learn more about ASAPP and how they can help your team? Request a Demo
Excellent, automatic transcription is mission-critical for digital CX transformation if you are looking to:
If you’re aligned with those aims, then the number one thing you need to look for is a transcription solution with no tradeoff between speed and accuracy. Here’s why:
Transcriptions can help both during and after the call. Your agents need to be able to see exactly what is said as it’s being said, clearing up confusion or accounting for different accents. They also need to be able to use that real-time data in other AI solutions like agent augmentation tools. So don’t compromise. High-speed, low-latency transcription is essential.

Most transcriptions get the easy stuff right and can capture over 80% of single words and phrases, but what is left over is the most complex and critical information. Make sure your transcription solution can track not only exactly what was said but also who said it.

Understanding the critical significance of both speed and accuracy, we purposefully engineered AutoTranscribe to excel in both aspects.
Speed and accuracy are paramount, but don't overlook the importance of customization capabilities. Once you have optimal speed and accuracy, focus on the solution's ability to adapt to the unique needs of your business. This ensures that your transcription solution remains efficient and effective, even as requirements evolve over time. Since transcription forms the bedrock of much of your CX technology stack, invest in a solution that's future-proof and won't require frequent replacements.
ASAPP AutoTranscribe is unmatched in the transcription landscape, offering high accuracy, best-in-class performance, tailored models, and rigorous evaluation.
With accuracy exceeding 89% and a latency of just 60ms, AutoTranscribe ensures no detail is missed in every call, which is crucial for both understanding and action.
Built on real-world data, AutoTranscribe achieves a word error rate (WER) of less than 11%, far surpassing generic services. Its tailored models adapt to each business's needs, capturing critical information accurately.
Real-time transcription capabilities enable swift problem-solving, enhancing agent efficiency and enabling real-time responses. ASAPP's commitment to excellence ensures continuous improvement, making AutoTranscribe a strategic asset for contact center operations.
For comprehensive insights into CX transcriptions and their transformative potential, download our eBook "The Modern CX Guide to Transcription." Explore best practices, technologies, and solutions to revolutionize CX with accurate transcription. Elevate agent efficiency, gain valuable business data, and harness the full potential of customer interactions.
Transform your CX strategy with the right transcription solution.
ASAPP is the AI-native software for contact centers, and ASAPP exists to end bad customer service. We help customer service leaders unlock their full value by minimizing costs & inefficiencies, improving agent compliance & productivity, and surfacing actionable insights while helping you deliver a great customer experience. Our customers are large enterprises who care deeply about leveraging AI to transform CX by delivering unprecedented cost savings and maximizing customer delight.
Want to learn more about ASAPP and how they can help your team? Request a Demo
The importance of highly accurate, fast, and automated transcription cannot be overstated. It enables organizations to unlock invaluable insights from customer interactions and is the bedrock for effectively leveraging AI technologies.
In the context of CX, transcription is the process of converting spoken interactions between customers and agents into accurate, textual representations. This entails capturing not just the words spoken but also the nuances and subtleties of each conversation, including tone, emotion, and context. These nuances are essential for understanding the intricacies of customer interactions, allowing businesses to tailor their responses and CX strategies effectively.
Good transcription transcends the mere conversion of speech to text, which is essential for effective communication, customer satisfaction, and detailed analytics. Every customer interaction holds valuable insights that drive improvement and innovation. Accurate transcription captures the nuances of conversations, ensuring data integrity and empowering your organization to confidently make informed decisions.
Good data leads to good decisions, which pave the way for effective strategies and strong customer relationships. When organizations have confidence in the data underlying their decisions, it leads to more focused actions, better customer experiences, and streamlined operations.

Your CX success hinges on selecting the right transcription solution. Without highly accurate, real-time transcription, your agents, AI solutions, and bots will lack the timely information necessary for effective operation. For instance, a low word error rate (WER) is crucial for precise entity extraction, vital in tasks like customer service chats or financial transactions. Entities such as order numbers, product names, and sensitive information require a WER of <10% for accurate extraction, ensuring reliable data processing.
Quality transcription forms the cornerstone for advanced AI applications like natural language processing (NLP), sentiment analysis, and predictive modeling. Without accurate transcription, your AI solutions will lack the necessary data to function effectively, hindering their ability to automate responses, predict trends, and tailor interactions with customers.
For comprehensive insights into CX transcriptions and their transformative potential, download our eBook "The Modern CX Guide to Transcription." Explore best practices, technologies, and solutions to revolutionize CX with accurate transcription. Elevate agent efficiency, gain valuable business data, and harness the full potential of customer interactions.
Transform your CX strategy with the right transcription solution.

ASAPP is the AI-native software for contact centers, and ASAPP exists to end bad customer service. We help customer service leaders unlock their full value by minimizing costs & inefficiencies, improving agent compliance & productivity, and surfacing actionable insights while helping you deliver a great customer experience. Our customers are large enterprises who care deeply about leveraging AI to transform CX by delivering unprecedented cost savings and maximizing customer delight.
Want to learn more about ASAPP and how they can help your team? Request a Demo
We are proud and thrilled to announce a revolutionary new product the likes of which enterprises have never seen before, GenerativeAgent®, a product that automates what was previously impossible to automate with our fully conversational generative AI voice and chat agent.
GenerativeAgent is a generative AI product that can automate 90%+ of contact center interactions. This revolutionary technology can handle complex interactions, helping customers more efficiently and effectively than ever before. Furthermore, it unleashes a new era of productivity by allowing agent concurrency for voice interactions–introducing a new paradigm for contact centers.
"This product isn't just groundbreaking—it's revolutionary, redefining what we thought was possible in what is likely the largest automation opportunity in the world today," said Gustavo Sapoznik, Founder and CEO, ASAPP.
Dramatic business savings:
- Greatly reduces the call volume to your agents
- Raises the ceiling of what you can automate
- Accurate, flexible, and secure
Increased customer satisfaction with:
- No time wasted
- No channel switching
- No transfers, for a seamless experience
GenerativeAgent is always online and ready to speak with your customers.
For far too long, companies have been spending fortunes that result in the alienation and frustration of customers; all the while, the agents in these contact centers have one of the highest attrition rates of any job. Technology so far has provided a few band-aids to aid in the problem of delivering excellent customer service at scale and at cost. Still, the reality is that nothing but incremental value has been delivered for the better part of the past forty years.
These incremental gains in capability over the years have resulted in an industry that is stuck in an unfortunate tradeoff where companies have to place themselves on a spectrum ranging from cost-effective yet poor customer service to prohibitively expensive and excellent customer service. All the while, frontline agents have been crushed beneath the sheer volume of interactions and tasks to accomplish, resulting in some of the highest turnover rates of any occupation. The truth is that employees were not built to thrive in this environment, and customers were not built to endure this environment.

GenerativeAgent finally breaks this tradeoff by allowing companies to deliver excellent customer service at scale while freeing up human agents to focus more fully on higher-tiered interactions and problem-solving.
“Organizations no longer have to make a trade-off between great customer experience and saving money. With ASAPP, doing what’s best for the company is now doing what’s best for the customer.” - Gustavo Sapoznik, Founder and CEO, ASAPP
GenerativeAgent is a fully capable generative AI voice and messaging agent. It is a completely autonomous system that automates interactions currently assigned to human agents. This results in a radically improved customer experience across all interaction channels and substantial business savings.
ASAPP's decade-long AI research and creation of state-of-the-art products has culminated in the breakthrough that is GenerativeAgent. The product is:
With GenerativeAgent, customers will be immediately connected with a capable, conversational, and flexible helper that will solve many of their questions or issues dependably and efficiently. Agents will be able to oversee multiple interactions at once, and can handle all escalations in real-time through GenerativeAgent.
Want to learn more and see it in action? Watch the full-length keynote presentation here.
None of these groundbreaking capabilities matter if you cannot trust it to deliver the right information to your customers, stay within your policies, and faithfully reflect your brand.
We built GenerativeAgent to be not only the most capable generative AI agent on the market but also the safest and most trustworthy. Read on to see just some of the steps that we have taken and the guardrails that we have built to ensure that GenerativeAgent can respond reliably, effectively, and safely to your customers.
GenerativeAgent leverages integrations into your APIs to retrieve data and take actions that are specific to each customer, enabling hyper-personalized automation. Your knowledge center is used to answer all questions about policies, products, or services and technical issues while maintaining up-to-date responses.
ASAPP utilizes state-of-the-art Language Learning Models (LLMs) renowned for their exceptional performance in (1) adhering to prescribed instructions, (2) deciphering potentially conflicting or vague customer input, and (3) mitigating the risk of generating inaccurate or unintended responses, ensuring utmost privacy and data integrity.
ASAPP integrates robust safety protocols designed to assess the safety of incoming inputs. Any queries deemed potentially unsafe are promptly flagged and rejected, safeguarding user privacy and security.
ASAPP subjects GenerativeAgent to internal and external evaluations conducted by both ASAPP personnel and trusted customers, ensuring that all interactions yield safe and reliable outcomes, thereby upholding our commitment to privacy and safety.
ASAPP's infrastructure facilitates seamless connectivity between agents and human operators, ensuring that GenerativeAgent receives timely assistance and oversight whenever encountering queries beyond its scope, thereby enhancing the accuracy and privacy of responses, with all escalations being handled through GenerativeAgent.
GenerativeAgent has been developed using, and will continue to be updated using, and will function consistent with, the present and future standards, guidelines, protocols, and policies applicable to, governing, or addressing AI, offering assurance to users regarding the protection and responsible handling of their data
ASAPP is an artificial intelligence cloud provider committed to solving how enterprises and their customers engage. Inspired by large, complex, and data-rich problems, ASAPP creates state-of-the-art AI technology that covers all facets of the contact center. Leading businesses rely on ASAPP's AI Cloud applications and services to multiply Agent productivity, operationalize real-time intelligence, and delight every customer.
GenerativeAgent is the latest in ASAPP's suite of generative AI customer experience products, including AutoSummary, AutoTranscribe, and the ASAPP Messaging platform. Fortune 500 organizations, including four of the top five cable providers, 50% of the leading wireless companies, two of the four largest airlines, and other leading enterprises across banking, insurance, retail, and technology, currently use ASAPP's state-of-the-art products and technology.
ASAPP’s journey to GenerativeAgent is the result not of following the technology trend and hastily incorporating “AI” on top of or into legacy products but of envisioning what products and technology should be and then doing the required hard work to make it happen. This work has resulted in over 100 patents, dozens of publications in top AI journals, and a continued development of the technology required to make our vision come to life over the past 10 years.
Customers change fast. Contact centers don’t. That’s precisely where summarizations can help. The integration of generative AI summarization solutions into customer experience strategies represents a transformative leap forward for the CX industry. Here’s what to consider when choosing a summarization solution that aligns with your needs.
The myriad friction points inherent in traditional summary processes that significantly limit the value extracted from customer interactions can now be overcome with the advent of modern summarization solutions. The arrival of generative AI capabilities marks a pivotal moment for summarization technology.
For the first time, businesses can automatically summarize conversations at scale and structure the resulting data in insightful and actionable ways. This capability was once a distant dream but is now an accessible reality, highlighting the importance of selecting a solution that leverages the latest generative AI advancements to deliver accurate and meaningful summaries. When the full potential of generative AI summarizations is harnessed, customer experiences are truly transformed.

Generative AI summarizations offer unparalleled benefits, especially when considering the demands placed on customer service agents. These people juggle numerous interactions and responsibilities, making it challenging to craft detailed, insightful, and meaningful summaries during or after customer interactions. An effective generative AI solution can alleviate this burden by automatically generating high-quality summaries that capture the essence of each conversation, ensuring consistency, reducing average handling time (AHT), and enhancing overall CX quality.
When evaluating summarization solutions, consider the following critical features to ensure you choose a system that meets your business’s unique requirements:
Generative vs. Extractive AI vs. Manual
When evaluating AI solutions, you'll encounter whether they use generative or extractive AI for summarizations. While extractive AI is traditionally favored for summarization, generative AI solutions can provide more flexibility and higher quality.
CCaaS vs. Point Solution vs. DIY
Consider your goals and the flexibility of the summarization solution. Large CCaaS vendors might restrict you to their ecosystem, while smaller AI vendors may lack enterprise-level features and scalability. Small CCaaS providers, often using less advanced models, might be expensive and not fully support enterprise requirements.
Dashboards and Data Connections
All of the great data you are harvesting is only useful if the people who need to consume it and gain insights from it are able to. Make sure you can get some out-of-the-box in-product dashboards for common CX insights as well as the ability to connect your aggregated data to other BI tools like Tableau or Power BI.
Customization and Flexibility
How flexible is the model, and is it improving over time? Ideally the solution you select will improve over time to better serve the unique nuances and needs of your company. Also, it will ideally allow you to adjust your parameters and your lens to find new insights or answer new questions from future conversations and past ones.
Make sure it will be human-readable
AI isn’t perfect, but there are solution capabilities to make AI as accurate and dependable as possible. When evaluating solutions, look for some of the following capabilities:
Robust structured data capabilities
To maximize the value of your investment, look for structured data that allows for an easy configuration of what metrics customers would like extracted and allows you to do that from day one. Beyond the data itself, the solution should also be able to enrich the data available to technical leaders. This opens up a world where structured summaries generated become a rich source of insight into customer interactions. Technical leaders will have the valuable data to inform crucial decisions, from ensuring compliance to shaping strategic initiatives like service optimizations and new product introductions.
Multiple contact reasons
Not every interaction is about a single issue. Your summarization solution should be able to support this so you can track the individual issues being addressed in a single interaction or over the lifetime of that customer.
Implementing the right generative AI summarization solution can transform your CX strategy by delivering:
The decision to invest in a modern summarization solution is a step toward unlocking the full potential of your customer interactions. By carefully considering the capabilities, integration potential, and the specific needs of your business, you can choose a solution that not only mitigates the friction points of traditional summary processes but also propels your CX strategy into the future.
ASAPP's AutoSummary stands out by harnessing the power of generative AI to deliver highly customizable, accurate summaries of all customer interactions. With its built-in Conversation Explorer, it provides deep insights into call transcripts and customer sentiment, enabling businesses to make data-driven decisions without the need for complex SQL queries. AutoSummary guarantees comprehensive summaries on every interaction, ensuring consistent quality along with structured data that seamlessly integrates with BI tools for enhanced analysis.
AutoSummary is designed to adapt, allowing for real-time adjustments to summaries based on evolving business and regulatory requirements. This focus on flexibility, combined with our ability to reduce average handling time and ensure data privacy, makes AutoSummary a leading choice for contact centers seeking to improve their operational efficiency and customer engagement with a powerful generative AI solution.
If you are sold on the need for automated transcription and summarization in your CX organization, then you need to know what to look for (and what to look out for) when evaluating solutions. Just “good enough” isn’t good enough when you are setting the foundation of intelligence for your CX organization.
This guide will help you understand the features and capabilities you need to keep in mind when evaluating solutions and the reasons why they are mission-critical for your organization. Read on to ensure you aren’t adding to your technical debt and that you are building a solid foundation for your AI journey with the right solutions.
The decision to incorporate AI into contact center operations is no longer a question of if, but how. Among the myriad options available, starting with a modern transcription + summarization solution stands out as a wise strategic move. This approach not only delivers immediate benefits but also lays a solid foundation for a comprehensive AI journey. While summaries can provide deep insights into customer interactions, your transcription service needs to be top notch in order for it to deliver exceptional value—a key factor we'll explore. Let’s look at summaries first.
Generative AI summary solutions offer a multitude of advantages that can transform your contact center business operations. They significantly reduce Average Handling Time (AHT), which means more customers getting what they want more quickly. By swiftly identifying and conveying the essence of customer interactions or business data, these solutions enhance customer satisfaction and empower agents with the insights they need to quickly solve customer issues.
Customer interaction summaries bring to the surface key customer data that might otherwise remain buried in the depths of unstructured information. The scalability of generative AI summaries means that no matter the volume of data, the quality and speed of summaries remain consistent, ensuring that your contact center can handle growth without compromising on service quality.
One of the standout features of generative AI summary solutions is their ease of integration. The most advanced solutions are almost turn-key, requiring minimal effort to implement into existing systems. This quick setup time means that contact centers can start reaping the benefits almost immediately. Summaries can also function as standalone solutions if needed, providing flexibility for businesses to adopt AI in a way that best suits their current needs. Yet, our experience shows that maximizing the value of summaries requires a high-quality transcription solution operating in sync.
There is one key capability to have in place that will be necessary to drive good summaries and most other technology solutions that you are looking to implement – good transcription. While we aren’t going to dive too deeply into the reasons for a transcription solution, know that it is table stakes.
The good news is that you can most likely bundle your transcription with your summary implementation. However, you should know that not all transcription solutions are capable of delivering the foundation that you need to build out not only good summaries, but the rest of your CX technology stack.
As you evaluate either your existing transcription solution or begin your search for a new one, keep the following key capabilities in mind:
You may have a data swamp of all of your past interactions. A modern transcription + summarization solution will turn that data swamp into an asset.
Taking your AI journey seriously involves more than just implementing isolated solutions; it requires building a structured, data-driven foundation. The right generative AI transcription + summary solution does exactly that. By structuring data from the get-go, you ensure that subsequent AI solutions have a solid base to build upon. This enhances the efficiency and effectiveness of future AI implementations and provides valuable insights that can guide strategic decisions about which areas, issues, or value drivers to focus on next—shaping a tailored AI solution strategy that aligns with business goals.
The scalability of generative AI transcription + summary solutions cannot be overstated. As businesses grow, the volume of data that needs to be processed increases exponentially. Having the right solution positions contact centers to handle this growth, regardless of the volume. This means that businesses can scale without worrying about diminishing the quality of their customer interactions or the insights derived from their data. Furthermore, the continuous improvement algorithms inherent in generative AI solutions ensure that the quality of data improves over time, providing increasingly accurate and relevant insights.
Implementing a generative AI transcription + summary solution offers a swift path to realizing tangible value. By reducing AHT and improving customer satisfaction, businesses can see immediate improvements in operational efficiency and customer experiences. The empowerment of agents with key insights and the surfacing of crucial business data can drive informed decision-making and strategic planning. And the quick implementation time and the potential for standalone operation make generative AI summaries a low-risk, high-reward starting point for any contact center looking for a quick start to their AI journey.
The insights gained from a modern transcription + summary solution are invaluable in shaping your broader AI strategy. They provide a blueprint for identifying which areas of your business can benefit most from AI, helping to prioritize future projects. This strategic approach ensures that each step of your AI journey is aligned with your business objectives, maximizing the return on your AI investments.
Starting your AI journey with a summary solution is not just a strategic choice; it's a foundational one. It offers immediate benefits, sets the stage for a structured data environment, and paves the way for a tailored, strategic integration of further AI solutions. By prioritizing a generative AI transcription + summary solution you're not just implementing a tool; you're laying the groundwork for a comprehensive, intelligent, and scalable AI framework that will drive your desired customer experiences.
AutoTranscribe and AutoSummary are the first step to enhancing your AI CX strategy with unmatched precision and customization. AutoTranscribe offers real-time, accurate transcription tailored to your needs, while AutoSummary delivers fast, detailed summaries focused on key topics or entities, ensuring vital insights are captured efficiently. Together, they provide a seamless, integrated experience, from data aggregation visualized through intuitive dashboards to robust data enrichment for deeper analysis. By incorporating AutoTranscribe and AutoSummary, ASAPP not only streamlines your operational processes but also unlocks new levels of insight and efficiency, making it the go-to choice for contact centers aiming to leverage the full potential of their customer interactions.
If you are sold on the need for automated transcription and summarization in your CX organization, then you need to know what to look for (and what to look out for) when evaluating solutions. Just “good enough” isn’t good enough when you are setting the foundation of intelligence for your CX organization.
This guide will help you understand the features and capabilities you need to keep in mind when evaluating solutions and the reasons why they are mission-critical for your organization. Read on to ensure you aren’t adding to your technical debt and that you are building a solid foundation for your AI journey with the right solutions. Read the guide here.